
NLP
Natural Language Processing is a field of linguistics and computer science focused on understanding the human language. NLP tasks include sentiment analysis, translation between different languages, information extraction, question answering, and so on. Application of these mechanisms surrounds us in our all-day life: search engines, chatbots, or even the lately famous ChatGPT are all based on NLP mechanisms. The term Natural Language Processing is very broad and regroups all of the algorithms, libraries, and tools that allow a computer to process natural language. Nowadays, most of those techniques are related to machine learning, which allows massive improvements in all of the existing tasks.
Semantic for machines
It is relatively easy for humans to handle natural language and to understand the meaning and nuances behind every word. Machines on the other hand are excellent at computing, therefore to be able to analyse linguistics with computers we need to find an accurate and efficient representation of words. Word embedding is a method that employs linguistic properties to transform words, sentences, or semantic concepts into vectors. Each dimension of the vector corresponds to a feature - a measurable characteristic present amongst all words. For instance, the word flower could be represented with the following vector:
flower : [0.5, 0.245, 0.971, 0.535 , 0.231, -0.257]
Vectors with hundreds of dimensions are common in this field. A simple approach to represent a word is the usage of a one-hot vector: a vector filled with zeros, except for a single element set to one. For $N$ different objects to encode, we will possess vectors with N dimensions. While this approach is straightforward, it has a major drawback: the complexity of all computing algorithms will explode with the number of dimensions. The Oxford English Dictionary contains around 600,000 words and existing algorithms applied to vectors with this many dimensions would require massive calculation resources. This curse of dimensionality is common amongst all fields related to machine learning and fueled much research about reducing the size of embeddings.

One-hot encoding vector example
Furthermore, this method of representing words fails to capture any meaningful relationships or similarities between them: features do not bring any information besides the identification of a word. Features should therefore be selected to differentiate words but also provide information about their meaning. In the earliest era of natural language processing, features would be manually selected. Research in machine learning leads to the creation of models able to identify the most important and sufficient set of features to properly differentiate words. This step in NLP pipelines is called feature selection.
Semantics for humans
Before detailing the technology that provided a solution to both the curse of dimensionality and feature selection, Let’s talk about the concept on which lies all NLP models to this day: the distributional hypothesis.
A bottle of tezgüino is on the table.
Everyone likes tezgüino .
Tezgüino makes you drunk.
We make tezgüino out of corn.
Before reading this, you had never heard of tezgüino, but after reading those 4 sentences using this word in different contexts, you are able to tell that it’s an alcoholic beverage that is made out of corn. This small example illustrates that the meaning of a word can be understood from the context it is used.
A bottle of cider is on the table.
Everyone likes cider.
Cider makes you drunk.
We make cider out of apples.
The above example illustrates the distributional hypothesis: words occurring in the same context have similar semantics. In our case, it is possible to swap tezgüino for cider if we also swap corn for apples for the sentences to be accurate. The distributional hypothesis serves as a baseline for Word2Vec and all of the latest improvements in terms of text generation.
Word2Vec
To have an effective method to represent words (or n-grams, or sentences) we needed a solution with a number of dimensions small enough to perform operations on embeddings and find a way to efficiently capture and store the semantics of words. Introduced in 2013, Word2Vec is a word embedding technique that employs a neural network model to discover associations between words by analyzing a corpus. Using unsupervised machine learning, Word2Vec results in the creation of a vector space with several hundred dimensions and automatically maps words into vectors. To generate distributed representations of words, Word2vec has two neuronal model architectures at its disposal: continuous bag-of-words (CBOW) or continuous skip-gram.
During the learning stage, both architectures take into account individual words and a sliding window of contextual words surrounding those individual words to assign weights. The CBOW architecture sets the vector weights by predicting the current word based on the context within the text. Whereas the skip-gram does the opposite and predicts surrounding words based on a given current word. Vectors’ dimensions are chosen at the beginning of the training and will infer the time the training takes but also its effectiveness in building an accurate vector space. The model will set the vector weights by itself and identify words with similar semantics by setting them close to each other in the vector space. More interestingly, the neuronal network will highlight patterns in natural languages. For instance, the distance (cosine distance) between the “Paris” and “France” vectors, is about the same as the distance between “Madrid” and “Spain” as shown below.
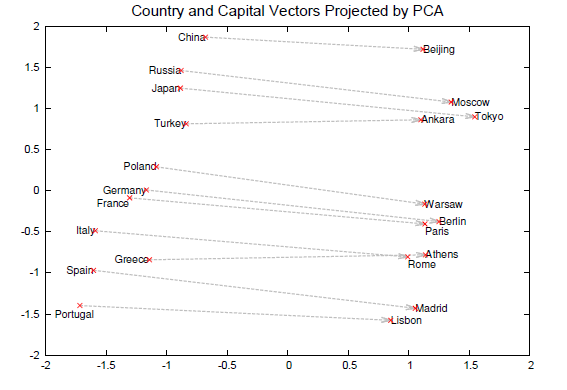
Capitals and their distance in the semantic space with their country
Thus, operations on vectors can also be used to reveal or retrieve interesting information. Using the same city and country example we have: Vec(Madrid) - Vec(Spain) + Vec(France) ~ Vec(Paris). While the concept behind Word2Vec was not new, the model’s performance and its availability to the public significantly contributed to its popularity.
Although Word2Vec is highly effective, it does have some limitations. For example, if a word has not been encountered in the training corpus, it will not have a vector representation, and the model will not be able to process it. Other technologies, such as FastText, address this issue by analyzing the semantics of subwords. Moreover, Word2Vec has limited support for polysemy, as its training corpus consists of articles from Google News, resulting in a more general rather than a specialized semantic understanding of words. This presents a challenge when attempting to solve problems in a specific domain, such as software engineering. For instance, a shell in this context is an interface between the user and the operating system, but Word2Vec may only associate the term with something found on a beach. To address this limitation, models with a fine-tuning layer or those trained on specialized corpus have been developed to better understand domain-specific jargon such as SO_Word2Vec for the software engineering domain.
Conclusion
To conclude, Word2Vec, FastText, and even their modern counterparts ELMO and BERT are all based on the concept of representing words, subwords, and sentences into vectors. The publication of algorithms, libraries, and more importantly pre-trained models led to the huge development of Natural Language Processing tasks (information retrieval, sentiment analysis, text summarization) over the last few years.
References:
- Google Word2Vec paper Distributed Representations of Words and Phrases and their Compositionality
- Original Tezgüino exampleAutomatic retrieval and clustering of similar words
- Number of words in Oxford English book: Oxford English Dictionary
- One hot encoding illustration: Word Embedding and One Hot Encoding
- Cities and countries image illustration: Learning the meaning behind words
- Software engineering specific W2V model: SO_word2vec